
SNIP: Bridging Mathematical Symbolic and Numeric Realms with Unified Pre-training
Intro
这篇论文中了 ICLR 2024 的 spotlight,4 个审稿人给出了 8 8 6 8 的高评价。其实,早在 2023 年 NeurIPS 的 AI4S track上,这篇论文就已经作为 poster 展示。这是一篇典型的 AI 本位论文,将最时下最新的多模态思想和预训练概念完美应用到了符号学习上,本文的思路十分严谨,并非简单的套用AI模型。
值得一提的是,本文一作 Kazem Meidani 老哥来自卡赖基梅隆大学(CMU),他同时也是 LLM-SR 的作者,那篇论文之后我应该也会发布精读笔记。
让我们言归正传,进入这篇论文的内容。
Motivation
SNIP 框架可以分为两部分,即数值编码器和符号编码器。
方法名 Symbolic-Numeric Integrated Pre-training (SNIP) 就比较有意思,和多模态领域的 Contrastive Language-Image Pre-training (CLIP [1]) 很相似,CLIP 是将图片与文本做对比学习,帮助模型获得图片和文字互相理解语义的能力,而SNIP把这样的对比学习对象从图片-文字换成了方程(symbolic)-数据(numeric),预训练得到的一个能理解从数据到方程的潜空间映射(世界地图)。以后,针对任何其他具体任务,不需要做特定的监督训练,能直接端到端给出一个对映关系。
SNIP 真正想回答的,不是“怎么把一个更强的模型塞进符号回归领域”,而是一个更前置、也更本质的问题:同一个科学对象,本来就天然同时存在于两个世界里——一个是符号世界里的方程,一个是数值世界里的观测。我们过去的模型,大多只站在其中一边说话。 现有工作要么从公式出发做数学推理(比如PINN,算子学习之类方法),要么从点集出发做符号回归(笔者老本行,往往就是给一组数据,用GA跑一个方程出来),而且通常都是围绕具体任务做监督训练;这样训练出来的模型,很容易学会某个任务的映射,却未必真的学会“这条曲线和这个公式为什么是一回事”。SNIP 的出发点,恰恰就是把这个缺口当作问题本身:先不急着做下游任务,先学会两种模态之间的对应关系。
所以作者的方法提出得非常自然。既然图像和文本可以通过对比学习形成共同语义空间,那么符号表达式和数值观测序列也可以。这就是 SNIP 的第一层motivation。但作者没有停在一个漂亮比喻上,而是很认真地问了第二层问题:这两种模态到底该怎么编码,哪些结构该保留,哪些结构该刻意忽略。于是我们看到一个很克制的设计:数值端和符号端都用 Transformer 编码,但两边不是简单镜像,而是各自尊重本模态的结构约束。
Method
具体来说,数值编码器处理的是一组 $((x,y))$ 点。作者沿用了此前 NeSymReS [2] 工作中的数值 tokenization,把浮点数转成 base-10 token;更重要的是,他们明确利用了点集的置换不变性,因此在 numeric encoder 中去掉了 positional embedding。
这里我想聊聊什么是置换不变性。在 NLP 任务中,一句话被 tokenize 后显然不是置换不变的,比如”你爱我“和”我爱你“具有完全不同的语义,因此语言模型中的 transformer 往往引入位置编码(positional embedding)来考虑 tokens 在输入序列中相对位置的影响。而在符号回归任务中,我们通常是不去考虑数据点的空间(位置)特性的,举例说,对方程 \(y = 4x^2, \tag{1}\) 我们给出的数据对 $(x,y)$ 很可能是局部采样,且不连续的,因此,我们训练一个 end-to-end 的模型时,不希望模型根据先给 $(1,4)$ 还是先给 $(0.5,1)$ 而改变输出的方程。这时候,以随意的顺序放入数据对可能就自然满足了置换不变的 bias。或者简单来想,不管 $x$ 取什么,只要 $y$ 服从方程给出的函数关系就行,方程形式不随输入的取值而产生改变。
符号端则相反,表达式按照前缀树序列化,保留顺序信息,因此 symbolic encoder 继续使用 positional embedding。两个编码器最终都经过 attention pooling (普通 pooling 是“平均一下”或者“取最大值”,而 attention pooling 是“让模型自己决定,哪些 token 更重要,然后做加权平均”)压成固定长度向量,落到同一个 latent space。补充材料里还能看到,两边编码器都配成了 8 层、16 头、512 维;这引来了 reviewer 追问,作者也明确回应:它们的设置比 Kamienny(E2E-SR [3])和 Biggio(NeSymReS [2])等先前工作更深,是因为这里不只是做任务拟合,而是要学 richer joint representations。
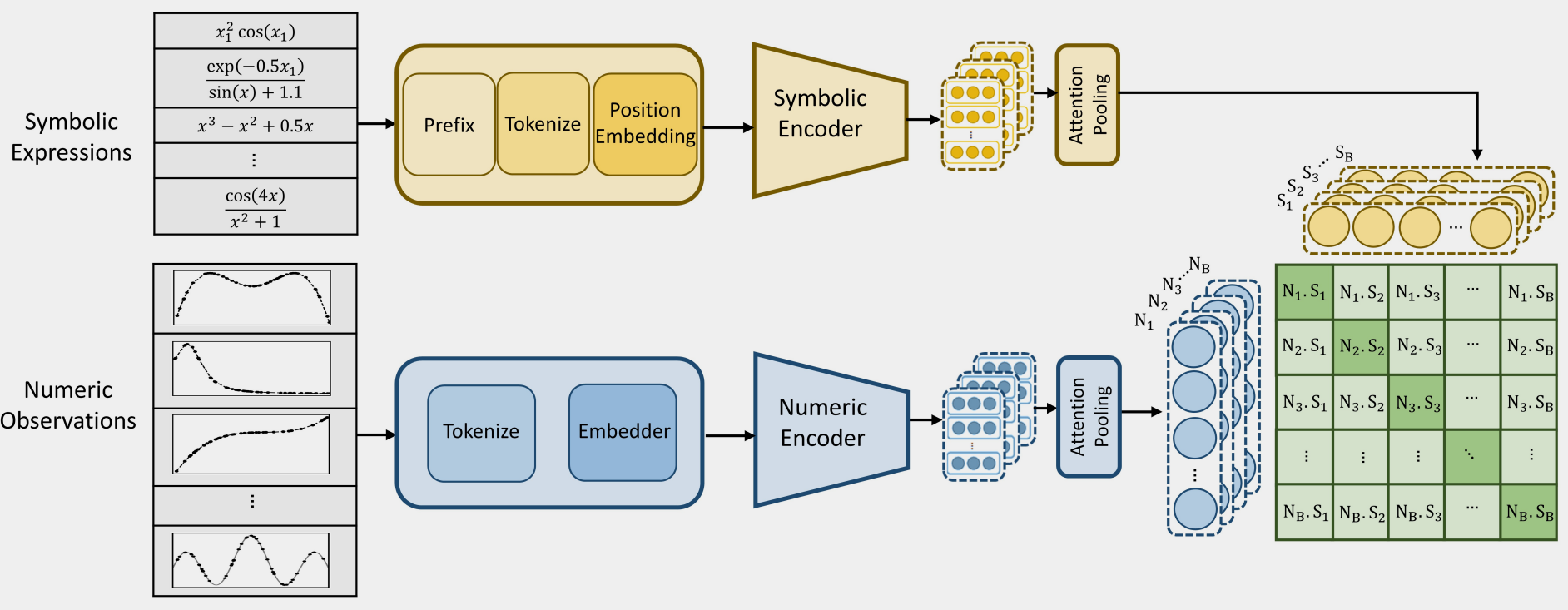
有了双编码器以后,SNIP 的核心就变得非常简单:对每个成对出现的“公式—数据”样本,做一个对称的 CLIP 式对比学习目标,让正确配对靠近、错误配对远离。该过程也是一个典型的无监督/自监督学习过程,此过程的代理任务为在batch内预测正确的 $(s_i,v_i)$ 配对关系,目标函数为一个对称的 InfoNCE 损失:
\[\mathcal L_{\text{SNIP}}= \frac{1}{2} \left( \mathcal L_{S\rightarrow V} + \mathcal L_{V\rightarrow S} \right). \tag{2}\]其中 symbolic-to-numeric 的损失为:
\[\mathcal{L}_{S\rightarrow V}= -\frac{1}{|\mathcal B|} \sum_{(s,v)\in\mathcal B} \log \frac{ \sum_{v^+\in V^+(s)} \exp\!\left(\frac{z_s^\top z_{v^+}}{\tau}\right) }{ \sum_{v'\in V(\mathcal B)} \exp\!\left(\frac{z_s^\top z_{v'}}{\tau}\right) }. \tag{3}\]对应地,$\mathcal{L}_{V\rightarrow S}$ 完全对称,只是把 symbolic 和 numeric 的角色互换。
从机制上看,这个损失一方面是拉近正配对:对应同一个函数的符号式和数值点集,它们的 embedding 相似度要变大。另一方面是推远错配对: 同一个 batch 里其他不对应的 $v_j$ 或 $s_j$ 都被当作负样本,让模型学会区分“这是同一个数学对象的两种表示”与“这不是”。
值得注意的是,作者指出了如何生成用于训练的合成数据:样本由随机函数生成,再采样数据点、清理超出定义域或数值爆炸的样本,并在预训练阶段把 $(y)$ 归一化到 $(0,1)$,强调函数行为而非数值尺度。最终,模型在训练中见到了大约 6000 万个合成的 symbolic-numeric pair。
Symbolic regression
接下来是把训练好的潜空间判别器拿来应用到下游的符号回归任务上。
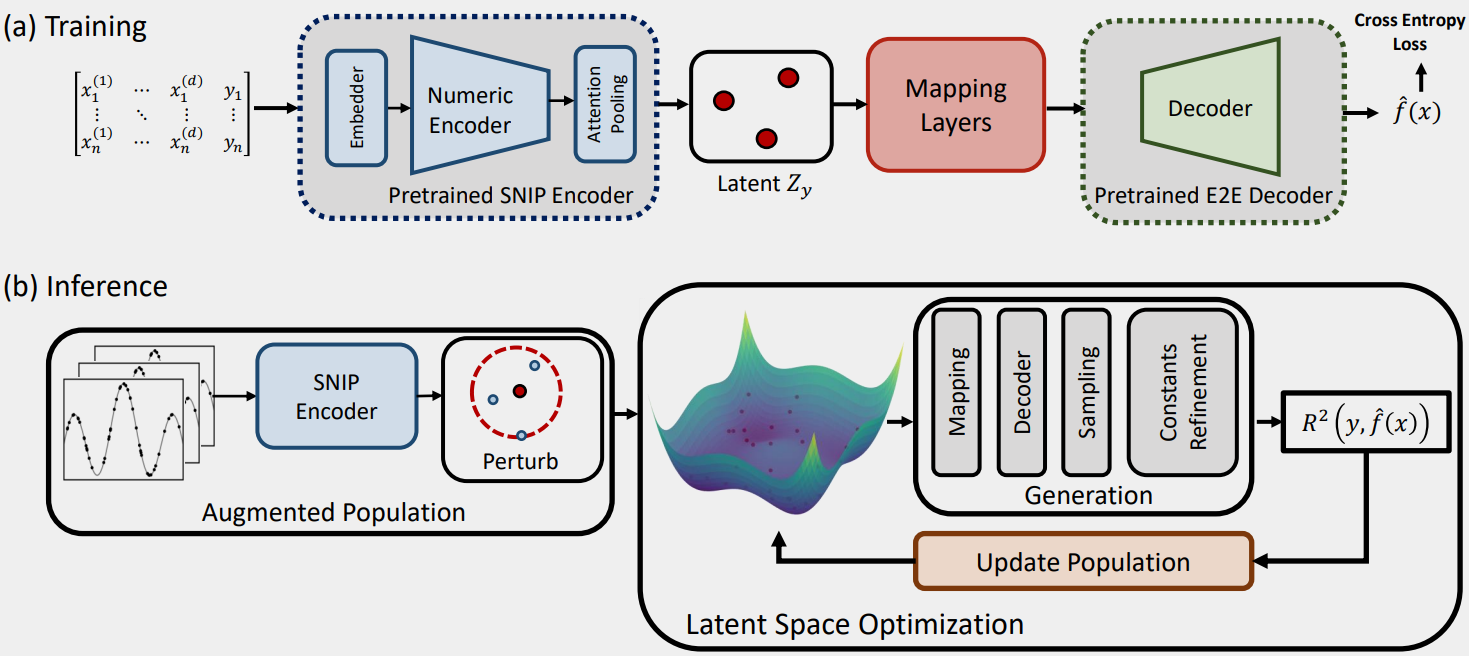
论文把预训练好的潜空间“判别器”真正接到符号回归上时,并不是直接让 SNIP 从数值点集端到端吐出公式,而是把 预训练的 numeric encoder 先当成一个更好的表征前端:输入一组数值观测 $v$,先得到其潜表示 $z_v$ 。但下游解码器仍沿用已有的 E2E symbolic regression 框架,因此作者额外训练了一个 mapping network (上图a中的红色部分),把 $z_v$ 映射成 decoder 可以接收的 token-like latent sequence,再交给已经预训练好的 expression decoder 生成公式。也就是说,SNIP 在这里不直接取代原有 SR 系统,而是先把“数据长什么样”编码得更好,再把这个表征喂给已有的公式生成器。这一段设计借鉴了 ClipCap [5]:结合预训练好的图片编码器和 GPT-2 的专业编码器,保留强大的生成端,只替换和重塑前端表示。
但作者并没有止步于此。他们更进一步意识到,如果 SNIP 学到的 latent space 真有语义结构,那么它不应该只被拿来喂 decoder 一次,而应该成为搜索空间本身。顺其自然的,作者提出了 Latent Space Optimization (LSO)。做法是:先围绕输入样本的潜表示初始化一批 latent population,再在连续潜空间里用梯度自由优化器不断更新这些 latent code;每一步都把候选 latent 解码成表达式,去重 skeleton、再对常数做数值优化,最后按拟合分数筛选最优公式。这样一来,符号回归就不再只是在离散公式树空间里硬搜,而是先在一个已经被 symbolic-numeric 对比学习塑形过的“语义潜空间”里找更有希望的区域,再把它译回显式公式。
很多 AI 研究者做 SR 时的直觉,是直接从 numeric input 到 symbolic output 搞一个 end-to-end seq2seq,SNIP 没有完全否定这条路,而是踩在了前人的肩膀上。这点实在是巧妙,SNIP 擅长的是“把数据编码好”,而不是“一步到位把表达式吐出来”。这种模块化复用,反而让整个方法更可信。这里也是笔者感悟很深的地方,很多时候做一个新方法并不是每个 component 都应该 design/build from scratch,往往 A+B+X 会比 X1+X2+X3 效果好,踩得坑也会少很多。
Experiments and results
实验上,作者没有只和一个 transformer baseline 比,而是直接放到经典的 SRBench [6] 体系里,与 E2E 以及经典 GP 类方法一起看 accuracy-complexity trade-off。他们评估了 119 个 Feynman、14 个 Strogatz、以及 57 个 black-box 数据集,并且由于复用了 E2E decoder,整个设置限制在连续特征、维度 ($D \le 10$) 的范围内。
结果很有说服力:SNIP 在三类数据集上都落在第一 Pareto front;在 Strogatz 上达到 0.928 的 top-tier accuracy;在 black-box 上以更低复杂度 47.52 超过 Operon 的 64.95;在 Feynman 上又同时展示出比 Operon 更低的复杂度、比 AIFeynman 更高的精度。
此外,作者在补充材料里做了严谨的消融实验:没有 LSO 时,($R^2>0.99$) 的平均成功率只有 0.683;加上 LSO 后,能稳定提升到 0.80+,这与 LSO 过程中使用梯度/无梯度优化器关系不大。可见 LSO 对提升准确率的巨大作用。
My thinking
这篇论文对符号回归乃至所有 AI4S 领域的研究者都很有启发。
- 不要把下游任务当作唯一入口。作者不是盯着 SR 本身开始研究,而是先问:SR 为什么难?难在 numeric realm 和 symbolic realm 之间没有一个共享语义层。这个问题一旦被提对了,后面的架构、预训练和优化几乎都是顺理成章的。很多时候,提升不是来自更大的模型,而是来自把任务往上抽象一层。
- 实验设计要能证明你方法的“中间假设”。论文不止 SNIP 给出了 SRBench 的基准表现,还插入了 cross-modal property prediction 和 latent space visualization,专门验证模型是否真的学到了共同语义。这类实验特别值得学习,因为很多论文的方法故事听起来都很顺,但缺的恰恰是对中间机制的验证。如何向读者证明我们好的根本原因,其中有很深的学问。
- 不要迷信纯 end-to-end。SNIP 把 representation learning、sequence generation、continuous optimization 三者拆开,又通过映射层和 latent search 把它们重新链接。这种“分而治之,再重新耦合”的思想,对科学发现类问题尤其重要,因为这类问题往往既有结构先验、又有搜索难度、还要求可解释。
- AI4S 里,预训练到底应该预训练什么。 SNIP 给出的答案是——不是预训练某个任务,而是预训练不同科学表述之间的对齐关系。可以看到,本文几乎没有做物理语义空间上的对齐,这是否是一个可行的方向?笔者未来应该也会尝试。
当然,本文中也讨论了 SNIP 的局限性:SNIP 仍然依赖闭式函数的数据生成协议,输入维度被限制在 ($D \le 10$),operator vocabulary 也受预定义语法约束;对那些本身就不适合被紧凑公式描述的模式,它并不总会 work。
Reference
[1] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 8748–8763. PMLR, 18–24 Jul 2021.
[2] Luca Biggio, Tommaso Bendinelli, Alexander Neitz, Aurelien Lucchi, and Giambattista Parascandolo. Neural symbolic regression that scales. In Marina Meila and Tong Zhang (eds.), Proceedings of the 38th International Conference on Machine Learning, volume 139 of Proceedings of Machine Learning Research, pp. 936–945. PMLR, 18–24 Jul 2021.
[3] Pierre-Alexandre Kamienny, Stephane d’Ascoli, Guillaume Lample, and Francois Charton. End-to-end symbolic regression with transformers. In Advances in Neural Information Processing Systems, 2022.
[4] 对比学习(Contrastive Learning),必知必会
[5] Ron Mokady, Amir Hertz, and Amit H Bermano. Clipcap: Clip prefix for image captioning. arXiv preprint arXiv:2111.09734, 2021.
[6] William La Cava, Patryk Orzechowski, Bogdan Burlacu, Fabricio de Franca, Marco Virgolin, Ying Jin, Michael Kommenda, and Jason Moore. Contemporary symbolic regression methods and their relative performance. In J. Vanschoren and S. Yeung (eds.), Proceedings of the Neural Information Processing Systems Track on Datasets and Benchmarks, volume 1, 2021.